The Red-Black Tree
Another self balancing data structure is the Red-Black tree. What are its properties? First, it is a binary search tree, so the search property is there obviously. And it's other properties? First off, each node has a color associated with it, either red or black, Doh. It then also needs to obey the following rules:
- The root is black.
- A red node only has black children.
- The path from any leaf to the root contains the same number of black nodes than the path from any other leaf to the root.
When we insert a value in the tree, we put it at the right location following the search property and color it red. This might break any of those properties, so we have to make sure they are fulfilled again. I am not gonna lie: Enforcing those rules is complicated, because there are so many combinations of colors the surrounding nodes might have. Checking for them is tedious, but straight forward. In fact Wikipedia lists 5 cases of colors of relative nodes for insertions to be taken into account and 2 simple and 6 non simple cases for deletion. The checks and fixes for the tree are easy and I will not repeat them here. In fact, my own implementation is more or less straight from Wikipedia.
The good thing is that most cases can be handled by only one or two rotations and some local recolorings. There is only one insertion case and one deletion case that needs to traverse the tree upwards again. This makes the Red-Black tree quite a bit cheaper than the AVL tree for those operations. The downside? It is not as strictly balanced.
Number of nodes in the tree
The number of black nodes in any path from leaf to root must be at least $$h/2$$. If we now use the assumption that each subtree of a node $$n$$ must contain at least $$2^{b(x)} -1$$ nodes; $$b(x)$$ is here the number of black nodes from $$n$$ to the root. This is easy to prove by induction.
Together, those two ideas give an estimation:
This is quite a big higher than the AVL tree was, remember? But still logarithmic, which is good.
Let's look at our canonical example as it will look with an Red-Black tree as container:
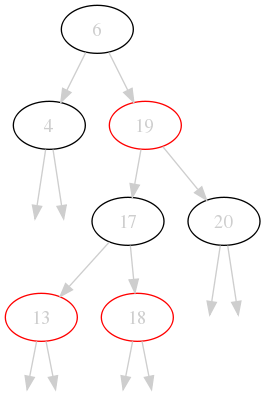
See. In a sense it is prettier than the AVL tree because it has colors! But it is also not so pretty because it is not so well balanced. But you can immediately check that the properties are fulfilled:
- The root is black.
- Each red node has only black children (or none).
- There are always 2 black nodes on each path from leaf to root.
So this is indeed a valid Red Black tree.
We looked at three types of binary search trees by now and we have implementations for all three of them available. What lies closer than benchmarking them?
Benchmarking
For the following tests I used two lists of values:
- A: the values from 0 to 2999 in random order. No duplicates.
- B: 1000 random values in the same range including duplicates.
I measured the time to
- insert all values from A into each container (insert column).
- delete all values from B from the filled container (delete column).
- search for all values from B in the filled container (search).
- construct a sorted list - that is an inorder traversal - from the filled container (iterate).
| Tree type | insert | delete | search | iterate |
| BS | 36 ms | 14.4 ms | 8.49 ms | 6.49 ms |
| AVL | 117 ms | 16.0 ms | 6.89 ms | 5.39 ms |
| RedBlack | 64 ms | 19.8 ms | 6.9 ms | 5.52 ms |
The timings are as expected: insertion and deletions goes fastest in the binary search tree (BS) because it doesn't need to do anything special. The AVL tree is slowest because it is most aggressive with balancing the tree. It gains ground on the red-black tree on deletion though: maybe the extra work on deletion is not so bad for the AVL tree; note it is still slower than the binary search tree.
Funny enough, searching and iterating is not really much faster in the AVL tree compared to the red-black tree. That shows why red-black trees are used so often: they are an excellent trade off in insertion/deletion speed compared to search speed.
Conclusion
Today, I presented you a very, very brief look at Red-Black trees. We only talked through the properties and looked at one example. I also finished the series with a benchmark for all three implementations.
You can find the implementations in the GitHub repository of mine. Take them for a spin yourself! If you are more of the theoretical type, go devour the Wikipedia page on Red-Black trees instead.
This concludes my series on binary search trees. If I feel so inclined, I might make another tree topic about B-Trees which I find particularly interesting.